About Myself
 Hi, I am Yuankun Fu (傅远坤), currently a researcher and PhD candidate at Purdue University. I work with my advisor Dr. Fengguang Song in areas of High Performance Computing.
Hi, I am Yuankun Fu (傅远坤), currently a researcher and PhD candidate at Purdue University. I work with my advisor Dr. Fengguang Song in areas of High Performance Computing.
Research Interests
- HPC: Parallel Programming Models & Runtime Systems, Advanced parallel algorithms, Automated performance analysis & optimization, In-situ analysis & visualization, GPU acceleration
- Cloud: Software defined networking (SDN), Distributed workflow, Data Storage
- Artificial intelligence: Distributed machine learning, Self-driving, Virtual reality
- Computational fluid dynamics: Lattice Boltzmann Method (LBM), Molecule dynamics, Large eddy simulation, Numerical analysis
Education and Work Experiences
-
May 2018 ~ Aug 2018, Los Alamos National Laboratory, Los Almos, NM
Graduate Research Assistant Intern
-
Aug 2014 ~ May 2021, Purdue University, IN
PhD Candidate in High performance computing, GPA 3.7
-
Sep 2011 ~ June 2014, Institute of Computing Technology, University of Chinese Academy of Sciences, Beijing, China
Master in Computer System and Archtechture, GPA 3.5
-
Sep 2007 ~ June 2011, Northeastern University, Shenyang, China
Bachelor in Electrical and Electronics Engineering, GPA 3.6, Top 3%
Publications
-
Yuankun Fu, Feng Li, Fengguang Song, Performance Analysis and Optimization of In-situ Integration of Simulation with Data Analysis: Zipping Applications Up. To appear in Proceedings of the 27th ACM International Symposium on High-Performance Parallel and Distributed Computing (HPDC’18), Tempe, Arizona, June 2018. [PDF]
-
Yuankun Fu, Feng Li, Fengguang Song, Luoding Zhu, Designing a Parallel Memory-Aware Lattice Boltzmann Algorithm on Manycore Systems, Proceedings of 30th International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD’18), Lyon, France, September 2018. [PDF]
-
Elliot Slaughter, Wei Wu, Yuankun Fu, etc. Task Bench: A Parameterized Benchmark for Evaluating Parallel Runtime Performance, SC 2020. [PDF]
-
Yuankun Fu, Fengguang Song, Luoding Zhu, Modeling and Implementation of an Asynchronous Approach to Integrating HPC and Big Data Analysis, 16th International Conference on Computational Science (ICCS’16), San Diego, California, June 2016. [PDF]
-
Yuankun Fu, Fengguang Song, SDN helps Big Data to optimize access to data, Big Data and Software Defined Networks, 297-318(504), Big Data and Software Defined Networks, Stevenage, UK, March 2018. [PDF]
-
Yuankun Fu, Fengguang Song, Designing a 3D Parallel Memory-Aware Lattice Boltzmann Algorithm on Manycore Systems, Euro-Par’21, Lisbon Portugal, 08/2021. [PDF]
-
Feng Li, Yuankun Fu, etc., Accelerating complex hydrology workflows using Vistrails and LaunchAgent coupling local and HPC/Cloud resources on-demand, 2021 IEEE 17th International Conference on eScience (eScience), 09/2021. [PDF]
-
Doctoral Dissertation: “Accelerated In-situ Workflow of Memory-aware Lattice Boltzmann Simulation and Analysis”, May 2021. [PDF]
Technical Skills
I use those tools intensively in my research workflow:
- Programming languages: C++, C, Python, Java, Scala, Matlab
- HPC related: Linux, MPI, OpenMP, Pthreads, GPU, CUDA/HIP
- Performance analysis tools: Intel Advisor / Vtune / Trace Analyzer, Roofline analysis, PAPI, TAU, Remora, Linux Perf, Nsight
- Big Data / Deep learning / Machine learning frameworks: Tensorflow, Pytorch, Apache Spark, Keras, Horovod, Weka
- Cloud/container solutions: Amazon AWS, Google Cloud Platform, Docker, kubernetes, Openstack, Redis, MySQL, SLURM, Grafana, Prometheus
- CI/Build tools: cMake, Ansible, travis CI, Google Gtest
- Computational fluid dynamics: Palabos, LAMMPS, OpenLB, Paraview/Catalyst, OpenFoam, Fieldview
- EDA related: Verilog, System-verilog, Altium Designer, Cadence, Xilinx ISE, Quartus II, mulTIsim
Featured Research Projects
- World’s fastest in-situ workflow system on HPC, Aug 2014 ~ June 2018, Purdue University, PhD Dissertation. Project-Zipper
-
Built the first in-situ workflow benchmark in the scientific workflow community. It integrated 7 state-of-the-art in-situ workflow systems with 3 synthetic apps, 2 real-world apps (LBM & LAMMPS Molecule dynamics), and real-world data analysis. Then detailed performance analysis using trace profiling tools showed that even the fastest existing in-situ system still had 42% overhead. - Developed a novel minimized end-to-end in-situ workflow system, Zipper, using C and MPI. It supported the fine-grain asynchronous and pipeline task parallelism, hybrid node proximity, fault tolerance, and achieved 96% efficiency of the ideal workflow performance model. Scalability experiments with 2 real-world applications using LBM and LAMMPS on 2 HPC systems using up to 13,056 cores showed that Zipper outperformed the existing fastest in-situ systems by up to 2.2 times.
- Invented a novel concurrent data transfer method, which used two channels, i.e., network and parallel file system, to transfer data with a multi-threaded work-stealing algorithm. This method reduced the data transfer time by up to 32% when the simulation was stalled. The speedup reason was then investigated by using OmniPath network tools, which showed that the network congestion was alleviated by up to 80%.
- Related publication: [HPDC’18], [ICCS’16], [SDN book chapter]
-
- World’s fastest Lattice Boltzmann method (LBM) algorithm, Nov 2015 ~ Present, Purdue University, PhD Dissertation. Project-2D Project-3D
- Designed novel parallel 2D & 3D memory-aware LBM algorithms to accelerate the memory-bound LBM simulation efficiently. It combined features of loop fusion, swap (reducing half of the data storage cost in 3D), spatial blocking (Tile in 2D, Prism Traversal in 3D), and temporal blocking (merging K time steps of LBM computation). Strong scalability experiments on 3 architectures showed that 2D & 3D memory-aware LBM outperformed the existing fastest LBM by up to 5 times & 1.9 times, respectively.
- Investigated the speedup reason using both theoretical algorithm analysis and experimental Roofline analysis. The arithmetic intensity (AI) of memory-aware LBM outperformed the fastest existing LBM by up to 4.6 times, and it transformed the critical memory-bound problem into a compute-bound problem on the Roofline chart of current CPU architectures.
- Used Paraview/Catalyst to visualize the Karman vortex street. Please click the following image to watch a “Karman vortex street” video generated by the memory-aware algorithm.
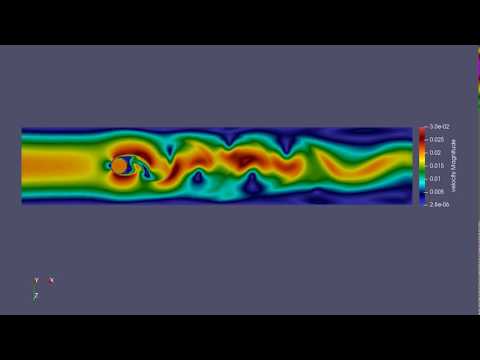
- Related publication: [SBAC-PAD’18]
- Designed novel parallel 2D & 3D memory-aware LBM algorithms to accelerate the memory-bound LBM simulation efficiently. It combined features of loop fusion, swap (reducing half of the data storage cost in 3D), spatial blocking (Tile in 2D, Prism Traversal in 3D), and temporal blocking (merging K time steps of LBM computation). Strong scalability experiments on 3 architectures showed that 2D & 3D memory-aware LBM outperformed the existing fastest LBM by up to 5 times & 1.9 times, respectively.
- Task Bench, Los Alamos National Laboratory, May 2018 ~ Aug 2018, Research intern project. Project-task-bench
-
Designed a parameterized benchmark Task Bench implemented in 15 parallel and distributed programming systems, including traditional HPC message passing models (MPI, MPI+OpenMP/CUDA), PGAS / Actor models (Chapel, Charm++, X10), task-based models (OmpSs, OpenMP, PaRSEC, Realm, Regent, StarPU), and models for data analytics, machine learning, and workflows (Dask, Spark, Swift/T, TensorFlow). For N benchmarks and M programming systems, it reduced the efforts of benchmarking and comparison from O(NM) to O(N+M). - Introduced a novel efficiency metric Minimum Effective Task Granularity (METG) to quantify the runtime overhead and amount of useful work performed in each system. Running at scale up to 256 nodes on Cori HPC, 100 us was the smallest granularity that the best system can reliably support with current technologies.
- Conclusion: Asynchronous systems have better overlap between computation and communication, and better support for complex task graphs. Compile-time optimization helps scaling for task-based models.
- Related publication: [SC’20]
-
- LaunchAgent: On-demand distributed workflow framework, June 2019 ~ Present, Purdue University, NSF project 1835817. Project-launchAgent
- Developed a Python library LaunchAgent that can be integrated into the local desktop VisTrails application to allow on-demand usage of HPC/Cloud resources for hydrology-related workflows. It manages authorization, prepares/submits batch jobs to those resources and monitors the quality of services for the users. This way, computation-intensive or data-intensive tasks from the workflow can be offloaded to powerful HPC/Cloud resources on demand. It is currently in use on 2 HPC systems and 3 Cloud systems (GCP, AWS and Jetstream).
- Built an AWS ParallelCluster configured with Amazon FSx for Lustre and NICE DCV for remote visualization. It contained a front-end to the Slurm scheduler, which was composed of an HTTPS API and a serverless function (AWS Lambda) that would translate the HTTPS requests to Slurm commands and run them through a secure channel. Then users could monitor the HPC Cluster with Prometheus, use Grafana to query and visualize system status.
- Built an elastic virtual cluster on XSEDE Jetstream resource in an k8s and Openstack environment. The basic structure is to have a single image act as headnode, with compute nodes managed by SLURM via the openstack API. The compute nodes use a basic CentOS 7 image, followed by an Ansible playbook to add software, mounts, users, config files, etc.
- Developed a Python library LaunchAgent that can be integrated into the local desktop VisTrails application to allow on-demand usage of HPC/Cloud resources for hydrology-related workflows. It manages authorization, prepares/submits batch jobs to those resources and monitors the quality of services for the users. This way, computation-intensive or data-intensive tasks from the workflow can be offloaded to powerful HPC/Cloud resources on demand. It is currently in use on 2 HPC systems and 3 Cloud systems (GCP, AWS and Jetstream).
- Bio-detection using unsupervised feature learning on limited biological dataset, Jan 2015 ~ June 2015, Purdue University, Course Project.
- Object-detection on total 1833 images with three different wavelengths for 4 classes of bacteria during 3 days. The classes exhibits multi-modal distributions. Random effects due to daily variations in experimental settings can be significant. The descriptive features across different bacteria classes can be subtle and not easy to define.
- Invented a Kmeans-based three-stage unsupervised feature learning method with data augmentation. First, it used multiple image scales and patch sizes to extract patches with normalization, then runs Kmeans to learn k centroids. Secondly, it used triangle encoding to obtain k dimensional assignment vectors, and sumpools these vectors, to obtain feature vectors representing images. Then it concatenated these feature vectors obtained at different patch sizes and image scales. Thirdly, it trained a SVM classifier using data on day 1, tuned its parameters using data on day 2, and tested data on day 3. Using only 400 descriptors, it achieved validation and test accuracy of 99% and 96.4%, respectively. This method mimicking the deep-learning behavior of multi-layer networks with improved stability, and can better tolerate random effects.
- Compared performance with deep learning techniques with Theano implementations of convolutional neural nets, Deep neural nets with dropout, and Stacked denoising autoencoder. Even using data augmentation, they achieve 52%, 49% and 56% test accuracy, respectively. They did not perform well as they rely on complex networks that are highly prone to overfitting when data are limited. Two conventional handcrafted features learning methods (Zernike moments and Haralick texture features) were also conducted and achieved 78% and 64% accuracy. Their high sensitivity to random effects makes them less ideal for classification with multi-day data sets.
- Object-detection on total 1833 images with three different wavelengths for 4 classes of bacteria during 3 days. The classes exhibits multi-modal distributions. Random effects due to daily variations in experimental settings can be significant. The descriptive features across different bacteria classes can be subtle and not easy to define.
- Minimal ResNet framework with efficient GPU kernels, Jan 2019 ~ May 2019, Purdue University, Course project.
- Led a team of 4 graduate students to build a ResNet C++/CUDA framework. I used cuDNN to implement the convolution forward and backward and global pooling GPU kernels on Google C++ Test framework. Results were verified by Numpy output.
- Scalability experiments showed that the cuDNN implementation using forward-winograd & backward-implicit-gemm kernels outperformed other algorithms by up to 12 times. The experiment was tested with the CIFAR10 dataset on Nvidia Tesla K40c & Quadro P6000 GPU.
- Distributed Multi-CPU sharing I/O Resource Pool on Dawning 7000 cloud system, 06/2012∼06/2014, M.S. Thesis, Institute of Computing Technology, Beijing, China
- Designed a novel PCIe network controller using FPGA to combine distributed I/O resources including NICs, SSDs, etc. into a shared resource pool, which can be accessed by CPUs on different sockets using PCIe with isolation and flexible resource re-allocation policy. It implemented MR-IOV (Multi-Root I/O Virtualization) based on SR-IOV devices (Single-Root I/O Virtualization) among distributed PCIe domains. Thus any virtual function of a SR-IOV device could be reallocated to any virtual machine of any CPU at runtime.
- The controller had three features: 1) direct I/O virtualization (building logic mirrors of the physical I/O devices on hardware to be compatible with existing hardware and software stack); 2) direct I/O mapping (ID mapping and address mapping of device functions in PCIe domain among root node and client nodes); 3) distributed PICe routing (routing PCIe data packet to the corresponding physical I/O device or remote root node).
- Built a NetDIOV verification framework using system Verilog, and perform MR-IOV functional test on Xilinx Virtex6 ff365t FPGA. Bandwidth performance test using iperTCP shows that it achieves 1.6GB/s using 32 double words with 125MHz clock rate.
Services
- Reviewer: SC’21, PEARC’21
Activities, Honors & Awards
Student Volunteer
- SC’2020 Conference, Atlanta, US
- SC’2018 Conference, Dallas, TX
Assisted with:
- Tutorial and session needs (a/v, recording attendance, etc)
- 30th Anniversary Point of Presence (Greeting people, answer questions, provide guidance, etc)
- SC19 Space Selection (Greeting exhibitors, Distributing gifts to exhibitors, etc)
Runner-up, Domestic Asia-Pacific Robot Contest (ABU Robocon), June 2009
- Designed the Drummer Robot hardware system, including power supply, microcontroller unit, driving circuit, and sensor acquisition circuit.
- Optimized the key devices’ information access strategy. Established the time sequence model of MEMS gyro drifting data, then processed it using Kalman Filter and stimulated the testing data with Matlab.
- Proposed the method of navigation and action control system, including the points for up or down action control, steering engine control, and the swaying action control.
Meritorious Winner, American Mathematical Contest in Modeling (MCM), Feburary 2010
- Designed a novel criminal geographic targeting(CGT) model, which computed every location’s relative probability of the criminal residence on a grid map and was visualized as a 3D contour.
- Trained a back propagation (BP) neural network with Levenberg-Marquardt algorithm using 100 serial criminals’ datasets. Then I used this model to predict the potential the serial criminal’s residence and his next crime location with 95% MSE accuracy (mean squared normalized error).
Second Prize, National Undergraduate Electronic Design Contest, September 2009
- Designed and implemented the hardware PCB system, including the pre-amplifier filter circuit, bandwidth-selection circuit, and the digital signal processing module using Altera FPGA. User can select continuous magnification of amplitude, power, and frequency.
For my spare time
I like traveling, sports and dancing.
Contact Me
I am avaliable via email at fu121 at dot purdue dot edu or fuyuan at iupui dot edu.
get connected with me in Linkedin!